3 billion human lives ended on August 29th, 1997. The survivors of the nuclear fire called the war Judgement Day. They lived only to face a new nightmare, the war against the Machines…
Skynet, the computer which controlled the machines, sent two terminators back through time. Their mission: to destroy the leader of the human Resistance… John Connor.
In the Terminator film franchise, an artificial intelligence system originally designed to protect the United States, seizes control of the world and launches a global war of extermination against humanity. For the moment thankfully, this is just science fiction- though it is understandable why when we hear the term “Machine Learning” that we immediately think of Arnold Schwarzenegger.
 Machine learning is infact a bonafide academic field of study. It is a subfield of computer science, and focuses on the development of computer programs (algorithms) that can teach themselves to learn or grow when exposed to new data. It is a relatively new field, but has rapidly gained in popularity with applications including: spam detection, speech recognition, recommendation algorithms (e.g. Amazon) and autonomous driving cars.
Machine learning is infact a bonafide academic field of study. It is a subfield of computer science, and focuses on the development of computer programs (algorithms) that can teach themselves to learn or grow when exposed to new data. It is a relatively new field, but has rapidly gained in popularity with applications including: spam detection, speech recognition, recommendation algorithms (e.g. Amazon) and autonomous driving cars.
Algorithmic Pricing
In the 1990’s British actuaries introduced Generalised Linear Models (GLMs) as a tool for analysing insurance data. GLMs have now become the default method for modelling claims costs, and are also widely used in renewal, conversion and lapse modelling. This article presents an algorithmic framework for building GLMs, using Lasso Regression – a predictive modelling technique taken from the machine learning community. This framework retains the familiar components of a GLM (linear predictor, link function, error term) but allows us to fit models in an automated way. As we will demonstrate, this allows us to test unstructured text data such as underwriter notes or social media activity in our pricing models.
Motivating Example: TheActuaryJobs.com Salary Prediction
TheActuaryJobs.com is the official job board for the Actuarial Profession. At the time of writing there were 757 live jobs listed, covering a wide range of experience levels, sectors and locations. Fortunately the structure of the website meant that it was relatively straightforward to scrape all 27,786 historic job advertisements. Thanks to Redactive publishing who gave us permission to use this data. Each advert contains information relating to the position which can be seen below.
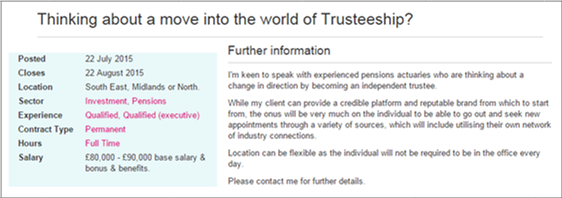
Our goal is to use the information provided in the job description to predict the probability that a given job advertisement pays more than £70,000. The information in the advert is a mixture of structured and unstructured text data, and we would like to test both data types in our model.
Continue reading here
Including unstructured data items such as free form text can dramatically increase the accuracy of your prediction models. To see how to do this continue reading by clicking on the following link: Judgement Day For Pricing which will take you to an article that appeared in the December 2015 edition of The Actuary magazine.
Find Out More
We are in the Big Data age and companies are looking to predictive modelling and machine learning to give them competitive advantage. To learn how machine learning can improve the predictive accuracy of your traditional insurance statistical models click here: Algorithmic Pricing
To get the most benefit from these predictive modelling techniques we shouldn’t restrict ourselves to the traditional structured data items, but wherever possible extend our reach to unstructured data items. Items such as customer comments and complaints, emails and any notes taken by internal staff are often available without looking outside the organisation and are a good place to start. To read how Statcore helped an organisation to unlock the value from their unstructured data sources click here: Topic Modelling
If you are interested in finding out more contact us.